Reading Time: 5 minutes
Wither the web search. You may have started putting in a date delimiter of ChatGPT’s arrival as a cutoff for reliable results on the internet. You may have hacked your default browser search to cut out slop. One thing is for sure: web search is not what it was. Thirsty AEO and GEO marketing is trying to pivot information providers but maybe that’s just more noise in this generative artificial intelligence feeding frenzy. Searchers know search is broken.
I taught my students the same search engine configuration I use myself. Well, not entirely. I regularly swap between major search engines (Microsoft Bing and Google) as well as using some of the Bing-infused tools like DuckDuckGo. As a rule, they only use one search engine, and that one search engine is Google. So when I use Google, it is always tweaked slightly to get rid of personalization (pws=0) and AI results (udm=14):
https://google.com/search?q=%s&pws=0&udm=14It’s still not great. I’ve noticed that the first page is still flooded with Google and Meta products, so I actually have a couple of other tweaks to my default search. This is even without applying additional filters. I find I need to use site filters (site:gov) and file filters (filetype:pdf) more often than before.
The beauty of web search was that the results were always a list of links. I could click them and determine relevance. Ideally, there were multiple good choices and it was a matter of finding one. Increasingly, I am paging deep into the search engine results pages (SERPs) to find relevant content. If I’m not looking for current information, slapping an “up to October 2023” time constraint can sometimes do amazing things to clean up results.
Legal research search is now also potentially generative AI infused. It’s been AI infused for most of the century, as has web search. It’s the emergence of generative AI that has led to more notorious bad outcomes for lawyers. But their hallucinated citations and misquoted law come as a result of a failure to verify and validate. These were always risks of using legal research technology, even with books.
It was somewhat amusing to me to see this play out recently when a court received a pleading and it had bad cites and bad law. Immediately the mind goes to generative AI, which is what both the opposing party and court expected. Nope. A paralegal had misunderstood the instructions and had found good law in cases outside the controlling jurisdiction and given those quotations citations that appeared to come from within it.
At bottom, it appears that Ms. Berrent—a paralegal responsible for substantively drafting briefs, including the MTD Opposition—misinterpreted Ms. Hiers’s guidance to cite to cases within the Third Circuit and made the regrettable decision to attribute quotations that were actually from cases outside the Third Circuit to cases within the Third Circuit. Ms. Berrent had accurately cited to these out-of-circuit cases in earlier drafts of the MTD Opposition, and seemingly swapped in the Third Circuit citations, making it appear as if the quotations came from those Third Circuit cases.
Gutierrez v. Lorenzo Foods, D. N.J. April 2, 2026 (2:24-cv-09173-EP-MAH)
And if you are in a role where you have to sign off on legal work product, that verification is crucial, whether you do the research yourself or delegate it to others.
Trust But Verify
This inability to validate links and verify contents frustrated some of my early attempts to use products. Some generative chat tools would refuse to provide citations, which immediately curtailed my interest. An answer engine should not be opaque but should, if anything, be able to show its output more clearly than something human generated.
But is it just information professionals who think like this? Certainly, it seems as though some lawyers do not. So I was glad to see a survey done by Yelp in conjunction with a consumer intelligence research company, Morning Consult, to see that this expectation is actually pretty widespread.
You can read more about the survey but they were interested in whether generative AI search was trusted. They found that, despite high use of generative AI, there was low trust. In addition, nearly 2/3ds of respondents double-checked the AI responses to their web search queries.
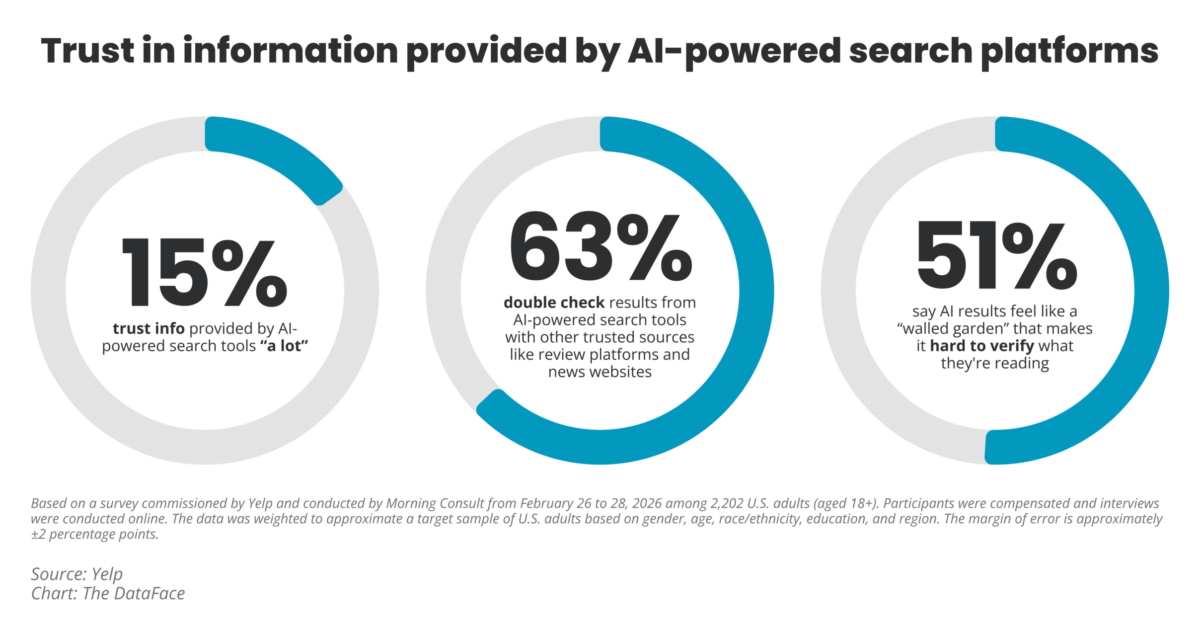
I think this is a very positive data point. I have seen this anecdotally with my students, who display both high use of web search, comfort with generative AI, and a great deal of skepticism about the latter. They may not be able to put it into words but I think there may be a manifestation of this same problem.
And it is the same problem for practitioners: generative AI is a productivity tool and agentic AI will be a productivity tool if it fulfills its potential. Both will require validation and verification that is similar to that required by delegation of work to a human. The question then becomes the same as it has ever been: is there a productivity gain by delegating or is that gain absorbed by the additional review required of the delegated work?
It’s All About the Gains, Bruh
Whenever search has come up, it has centered around the search box. The idea was that if you could just get people to the search box—on the website, on the library catalog, wherever—you could place all of your information behind it and make it findable. That’s not the case any longer. There is no guarantee that if you make information available via search or even expose it to search crawlers, that people will reach it.
This entire environment has become adversarial. The SEO marketing people have run forward towards new ways to min-max content visibility. Answer Engine Optimization and Generative Engine Optimization are overlapping terms that provide guidance for how to get web-based information into generative AI chatbots. An early proponent of this concept came out from some Princeton researchers and they positioned it as if it was generative AI chat would replace search engines. But their research found that the same approaches people were taking to making their content findable worked for both web search and generative AI chat.
There has also been a fundamental shift on the part of the information providers. In the past, people wanted Google and Microsoft to crawl their content so it was searchable. There was a mutually beneficial arrangement. That no relationship no longer exists. Information providers and crawlers are adversaries now. I thought this post on Fast Company summed up the issue: GEO is a mirage and the fundamentals are still the most important.
You may already have noticed this. Some of you have kindly reached out to let me know that you have been blocked from reading a post. I do my best to fix those access issues but I am spending a lot of time trying to limit the access to the site by bots, particularly AI-related bots. As I’ve mentioned before, it’s not that I don’t want my access visible but that the bots extract the system resources indiscriminately, causing the site to become unavailable to humans.
(http.referer contains "oogle") or
(ip.src in $garbage_out) or
(cf.verified_bot_category in {"Academic Research" "Accessibility" "Advertising & Marketing" "AI Assistant" "AI Crawler" "AI Search" "Archiver" "Aggregator" "Feed Fetcher" "Monitoring & Analytics" "Other" "Page Preview" "Search Engine Crawler" "Search Engine Optimization" "Security" "Social Media Marketing" "Webhooks" }) or
cf.client.bot or
(http.user_agent eq "") orThis is some of the Cloudflare firewall code I have in place to try to minimize unwanted visitors. The flipside to this is that my website will, hopefully, not appear in those generative AI tools. While I’m not engaged in active poisoning of generative AI, it is my goal to opt out of their results set.
My site isn’t the point. But the value of web search was always that it had a very wide reach and brought in expertise that wasn’t always available in visible platforms. As generative AI chat tools are used in place of web search, or where web search like Google and Microsoft place generative answers before direct content links, the searcher will not only be faced with a need to verify and validate those results. They may be working with a much smaller set of results than had the search been done without the AI inclusion.
The ultimate outcome is that the researcher won’t know. They will know that, as the Yelp survey points out, they may need to do more validation and verification of anything the generative AI tool provides in an answer. They may also need to know that the generative AI tool, especially if it is not attached to a large search index (so OpenAI products contrasted with Google products), is specifically not incorporating certain information.
It makes me wonder if we will see the same sort of narrowing down we saw in web search. We went from Ask Jeeves, Altavista, Excite, Google, and many more down to really just Google and search-engines-using-Bing’s-index. That has begun to change with Mojeek (who I mistrusted in the past but who are on my WAF allow list now to ensure they can index me) and pay-to-search Kagi and other search engines.
None of them may take market share from Google but that isn’t really the concern for a researcher. It’s productivity. We may need to be spending more time exploring, and recommending, lesser known but more reliable search engines so that we can cut down on the need to validate and verify the output of answer machines.